سیستم های هوشمند پیشنهاد دهنده در تجارت اینترنتی (فصل دوم)

لطفا برای مطالعه فصل اول این مقاله کلیک نمایید.
همانگونه که در فصل قبل توضیح داده شد، شرکت های اینترنتی به دنبال سبقت از رقبا راهکار جدیدی را پیاده سازی کردند که به نام سیستم های هوشمند پیشنهاد دهنده معروف شد. کار اصلی این سیستم ها پیشنهاد موارد مورد پسند کاربر در کمترین زمان ممکن است.
در یک فروشگاه اینترنتی با موضوع فروش فیلم ، از دو روش ضمنی و صریح برای جمع آوری اطلاعات استفاده شد. در مورد پیشنهاد یک فیلم DVD، ویژگی های فیلم با یک بردار مشخصه نشان داده شد. از جمله ویژگی ها می توان به نوع، کارگردان، بازیگران و غیره اشاره کرد. از یک سری فرم های پیش فرض هم برای ورود اطلاعات توسط کاربر استفاده شد.
برای استخراج ویژگی ها از کلیدواژه های معرف فیلم استفاده شد. برای مثال، پارک ژوراسیک با کلماتی مانند حمله، همزاد، دایناسور، آزمایش، ژنتیک و … معرفی شد. با استفاده از کلیدواژه ها کروموزوم های مورد استفاده در الگوریتم ژنتیک ساخته شدند. شکل زیر ، سیمای کلی پروفایل مشتری و روابط تابعی با عامل های مختلف را نشان می دهد.
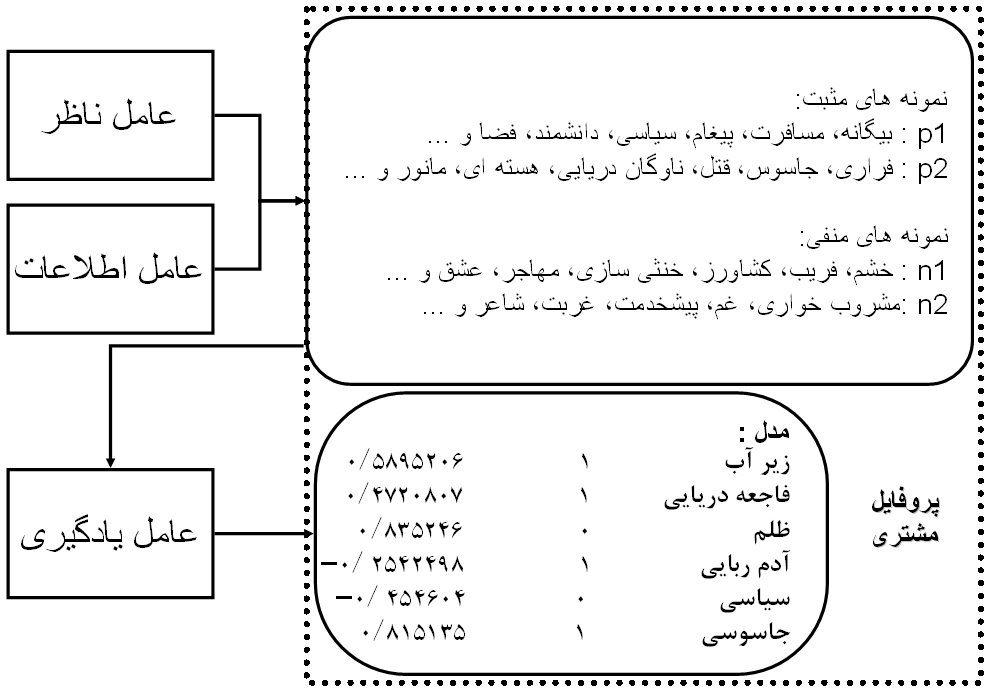
یک نمونه پروفایل کاربر. قسمت بالایی چند نمونه مثبت و منفی را نشان می دهد و قسمت پایین مدل استخراج شده از اطلاعات است.
در این سیستم، هر فرد(کروموزوم) با دو رشته از مقادیر عددی مشخص شده است.رشته اول که با a1,a2,…,an نشان داده می شود معرف ویژگی های محصولات است(در این نمونه کلید واژه ها) و هر ژن ai عدد ۰ یا ۱ است. رشته دوم اهمیت نسبی هر ویژگی در رشته اول را بیان می کند و با b1,b2,…,bn نشان داده می شود. هر ژن bi عددی اعشاری بین -۱ و +۱ است که وزن مربوط به ویژگی موردنظر را نشان می دهد.
با ساختار بالا ، برای پیش بینی علاقه مشتری به کالای خاص P، ابتدا کالا را به یک بردار n بعدی انتقال می دهیم تا خصوصیات تعریف شده اولیه را مطابقت دهیم، وسپس مجموع حاصلضرب وزن دار و مدل مشتری را به صورت زیر محاسبه می کنیم:

(Pi : مولفه iام بردار باینری کالای P و نشان دهنده این است که آیا ویژگی iام کالا در P ظاهر شده است. ai و bi مولفه های iام رشته های دسته بندی هستند که قبلاً معرفی شدند. و n طول دسته است.)
حوزه امکان پذیر مجموع وزن دار بالا، می تواند در چندین بازه فرعی تقسیم شود که هر بازه معرف یک درجه خاص از اولویت است، سپس درجه علاقه یک مشتری نسبت به کالای خاصی، به وسیله بررسی بازه فرعی اندازه گیری می شود.
در فاز یادگیری، عامل یادگیری از کالاهای ثبت شده در پروفایل مشتری به عنوان نمونه استفاده کرده و مکانیزمی تکاملی را برای انتخاب ویژگی های مناسب و تعیین وزن های مربوطه برای مدل اولویت های مشتری به کار می بندد. در طول فرایند تکاملی، هر مدل(کروموزوم)، برای پیش بینی نمونه های پژوهشی که مشتری علاقه دارد، بوسیله محاسبه مجموع وزن دار به کار می رود. برای هر نمونه، تفاوت بین بازه واقعی که به وسیله مدل ساخته شده و بازه مطلوبی که مه مشتری نمایش داده ، به عنوان خطای پیش بینی معرفی می شود، و مکمل آن به عنوان درجه صحت. بنابر این، میانگین دقت همه موارد نمونه به عنوان تابع شایستگی هر مدل معرفی می شود. مدل استنتاج شده در پروفایل مشتری ثبت می شود و برای پیشنهادات بعدی به کار می رود.
در جریان آزمایشات بر روی دو عامل یادگیری و کارایی تمرکز کردیم. برای عامل یادگیری، ابتدا پیش بینی یک مدل توسط الگوریتم ژنتیک(GA) را بررسی کرده و سپس مقایساتی با متد K-NN (شبکه های عصبی) انجام شد. با نظارت بر نوسان کارایی سیستم در زمان تغییر علایق کاربر به بررسی عامل کارایی پرداختیم.
از الگوریتم ژنتیک برای استخراج مدل های اولویت مشتریان استفاده شد. برای نمونه ها یک مقدار آستانه (T)، تعیین کردیم.اگر مجموع وزنی هر قلم جنس از T بیشتر بود، مورد علاقه کاربر و اگر از –T کمتر بود مورد نفرت کاربر است.(موارد بین T و –T پیش بینی های اشتباه نام دارند). نمودار شکل زیر همگرایی سیستم تکاملی را باT=0 نشان می دهد.

منحنی بالایی، درجه صحت بهترین مدل استنتاجی در هر نسل و منحنی پایینی میانگین درجه صحت همه جمعیت مدل ها را نشان می دهد.
برای بررسی کارایی مدل های آتی از روش معروف K-NN با سه مقدار منفاوت برای K (1 ، 3 و 5) استفاده کردیم که مشخص شد روش GA نتایج بهتری در پی دارد.
نمودار شکل زیر تغییر کارایی سیستم را با توجه به تغییر علایق یک کاربر در طول ۹۰ پیشنهاد نشان می دهد.

در این شکل هر نقطه معرف تعداد موارد پیشنهادی صحیح از ۱۰ مورد را نشان می دهد. مشاهده می شود که با تغییر علایق کاربر در بیستمین(و شصتمین) موردکارایی سیستم به شدت کاهش می یابد و زمانی به حد مطلوب می رسد که اطلاعات کافی درباره وضعیت جدید جمع آوری شود.
نوع دوم RS نیازمندی های یک مشتری را تحلیل کرده و ایده آل ترین محصول رابرای وی پیدا می کند. سیستمی که برای پیشنهاد کامپیوتر ارائه کردیم دارای سه عامل است: یک عامل واسط، برای تعامل با مصرف کننده. یک عامل خبره، برای انتقال دانش خبره خارجی جهت استفاده داخلی. و یک عامل تصمیم گیری برای محاسبه بهینگی هر محصول. این معماری در شکل 5 نشان داده شده است.
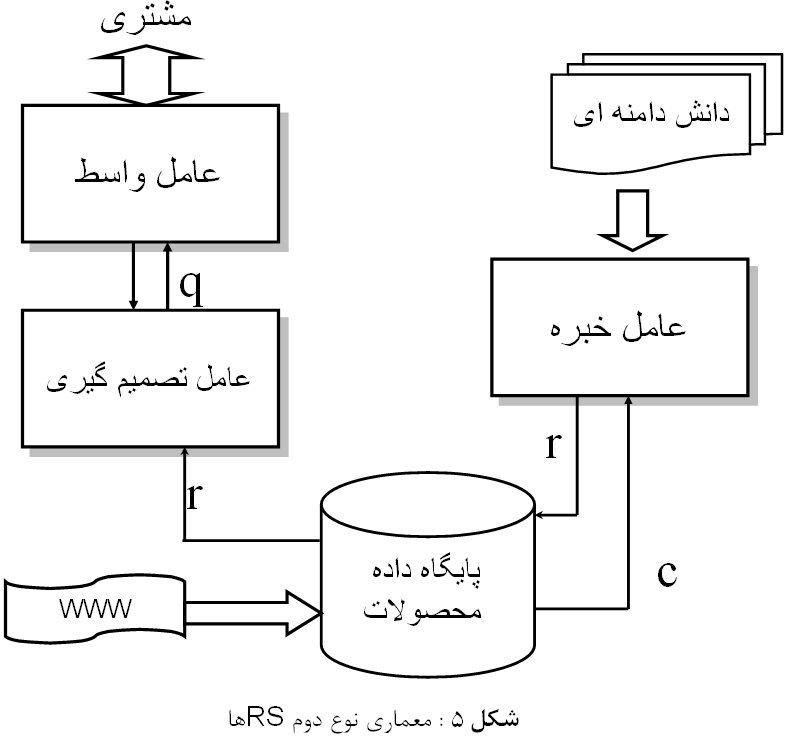
عامل واسط به وسیله پرسش های از پیش تعیین شده کمی و استخراج برخی اطلاعات به صورت کیفی، نیازهای مشتری را جمع آوری کرده و به عامل تصمیم گیری تحویل می دهد. عامل تصمیم گیری برای یافتن کالای ایده آل یک نگاشت بین نیازها و صفات کمی محصولات برقرار می کند.
هر کالا با تعدادی ویژگی در پایگاه داده تعریف می شود. ویژگی های کالاها بارشته ای عددی برچسب گذاری می شود که درجه توانایی کالای خاصی را در آن ویژگی بیان می کند. از طرفی خصوصیات کیفی که مشتری در نظر دارد به یک بردار تبدیل می شود. با تبدیل ویژگی های کارکردی۱ کالا به توانایی های کارکردی، بهینگی هر کالا تعیین می شود. یعنی هر کالا از یک لیست ویژگی های کمی به یک لیست ویژگی های کیفی نگاشت می شود.
یک کالای Pi به وسیله یک بردار از توانایی های اصلی (a1i,a2i,…,ani) توصیف می شود.هر مقدار aij، یک رتبه برای کارایی نسبی کالای Pi از میان کل مجموعه کالاها در توانایی اصلی j است. در نهایت، Pi به صورت (r1i,r2i,…,rni) نشان داده می شود که هر rji بین 1 تا 5 است. پس از شرح نیاز مندی ها توسط مشتری، بهینگی R از یک کالا در پایگاه داده از رابطه زیر محاسبه می شود:
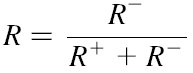
در حالی که داریم:
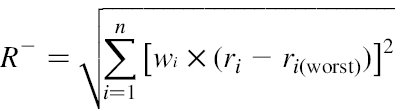
و
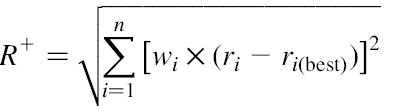
در رابطه بالا :
n : تعداد خصوصیات کالاها. ri : رتبه هنجارسازی یک کالا در بعد ویژگی I ، r i(best) و r i(worst) بهترین و بدترین رتبه ها در ابعاد یکسانند و wi نیاز نسبی مشتری در این ویژگی.
اندازه گیری بالا بر اساس این قاعده کلی است که : راه حل انتخابی باید کمترین فاصله را تا راه حل ایده آل داشته باشد و بیشترین فاصله را تا عکس ایده آل. کالاهای موجود، با ملاک بالا امتیازدهی می شوند. کالایی با بیش از ده امتیاز به کاربر پیشنهاد می شود. اگر مشتری راضی نشد، می تواند با تغییر درجه نیازمندی ها و علایق خود به پیشنهاد های جدیدی دست پیدا کند.