آلودگی اطلاعات در سازمان و شیوه های مقابله با آن (2 از 2)
مقدمه:
اگر مباحث قسمت اول از اين مطلب را مطالعه كرده باشيد، مفهوم آلودگي اطلاعات را به خوبي ميشناسيد. در ادامه قصد داريم راهكارهاي مواجه شدن با آلودگي اطلاعات را مورد بررسي قرار دهيم. لطفا با مجله اينترنتي گويا آيتي همراه باشيد.
مواجهه با آلودگي اطّلاعات
دو راهكار پيشگيري [1] و برطرف كردن [2] را ميتوان براي مواجهه با آلودگي اطّلاعات در نظر گرفت:
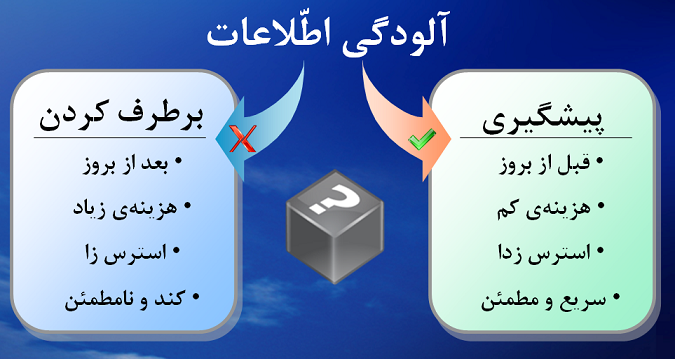
جدول 1: پيشگيري و برطرفكردن آلودگي اطلاعات
پيشگيري :
|
بر طرف كردن :
|
راهكاري مناسب براي پيشگيري از آلودگي اطّلاعات
بهترين روش براي پيشگيري از رخداد آلودگي اطلاعات در سازمان (يا در رايانهي شخصي) اين است كه دادههاي ورودي به رايانه (فايلها، ركوردهاي بانك اطلاعاتي و …) را به دقت كنترل كنيم. قبل از اين كار، لازم است استانداردها و قواعدي تعريف كنيم كه بر اساس اين استانداردها دادهها به سيستم مورد نظر ورود پيدا كنند و هيچ دادهاي بدون در نظر گرفتن اين قواعد وارد سيستم نشود. اين روش را طي چند گام با هم مرور ميكنيم:
- دانش سازمان خود را بالا ببريد: به اين مفهوم كه با آموزش مطالب روز در مورد حيطهي كاري سازماني كه مديريت آنرا بر عهده داريد، كارمندان خود را به روز نگه داريد. كارمنداني كه به روز هستند كمك بزرگي به سازمان در تشخيص اطلاعات به درد بخور از اطلاعات به درد نخور ميكنند.
- به افرادي كه با سيستم شما در تماس هستند آموزش بدهيد: با تهيهي راهنماها[3] و دستورالعملهاي مربوط به نامگذاري و آرشيو و رد و بدل كردن دادهها در سازمان، به افرادي كه با سيستم سر و كار دارند بياموزيد كه دادههاي به درد نخور را حذف كنند. دادههاي قديمي را ويرايش و به روز كرده و نسخههاي پيشين را از گردش كاري حذف كنند. (مگر اينكه سياست سازمان بر اين باشد كه تمام نسخههاي مستندات را ذخيره بايگاني كند) به كاربران و كارمندان بياموزيد كه نسخههاي كپي مختلف از يك فايل ايجاد نكنند. برخي افراد عادت دارند نسخههاي مختلفي از فايلها را در درايوهاي مختلف هارد ديسك ذخيره كنند كه در صورت از بين رفتن فايل، نسخهي پشتيبان داشته باشند. اين كار لازم نيست. به جاي آن سرور پشتيبان[4] راه اندازي كنيد.
- نرمافزار ضد ويروس مطمئن خريداري كنيد و آن را هميشه به روز نگه داريد: اطلاعات يكي از مهمترين داراييهاي سازمان است. اگر دزديده شود، اگر از بين برود، اگر مخدوش شود، ضرري كه ايجاد ميشود تقريبا غير قابل جبران است. اگر سختافزار تخريب شود، ميتوان آن را مجددا خريداري كرد. اما اطلاعاتي كه توسط شما توليد شده باشد، در صورت از بين رفتن، در جاي ديگري وجود ندارد كه بخواهيد آن را مجدد خريداري كنيد.
- از تكنيكهاي نامگذاري استاندارد براي ذخيرهي فايلها استفاده كنيد: فايلها را با زبان انگليسي درون سيستم ذخيره كنيد. نامهايي كه از چند كلمه تشكيل شدهاند را توسط يك نوع جداكننده[5] ثابت يادداشت كنيد. اينطور نباشد كه اسامي برخي فايلها با كليد فاصله[6]، برخي ديگر با خط تيره[7] ، برخي با خط ربط[8] و برخي ديگر با زيرخط[9] از هم جدا شده باشند. اين كار جستجوي اطلاعات را نيز سادهتر ميكند. اگر در اسمگذاري فايلها، كوچك و بزرگ بودن حروف برايتان مهم است، همهجا اين قاعده را به طور يكشكل رعايت كنيد. اگر چند فايل مرتبط به هم داريد، مثلا 2 تصوير از لوگوي سايت گويا آيتي، آنها را به طور مشابه و با شمارهگذاري تعيين نام كنيد. مثلا: Gooyait_Logo_1.jpg و Gooyait_Logo_2.gif
- يك ساختار شمارهگذاري براي تشخيص نسخههاي مختلف فايلها ايجاد كنيد و به آن پايبند باشيد. مثلا ميتوانيد تاريخ توليد يك فايل را نيز در نام آن بياوريد. يا مثلا شماره نسخه [10] به نسخههاي متعدد يك فايل اختصاص دهيد.
- براي دستهبندي انواع مختلف فايلها از پوشهها استفاده كنيد. سعي كنيد تا جاي ممكن انواع فايلهاي مختلف را درون يك پوشه در كنار هم نداشته باشيد. مثلا ميتوانيد ساختار پوشهبندي را اينگونه ايجاد كنيد:
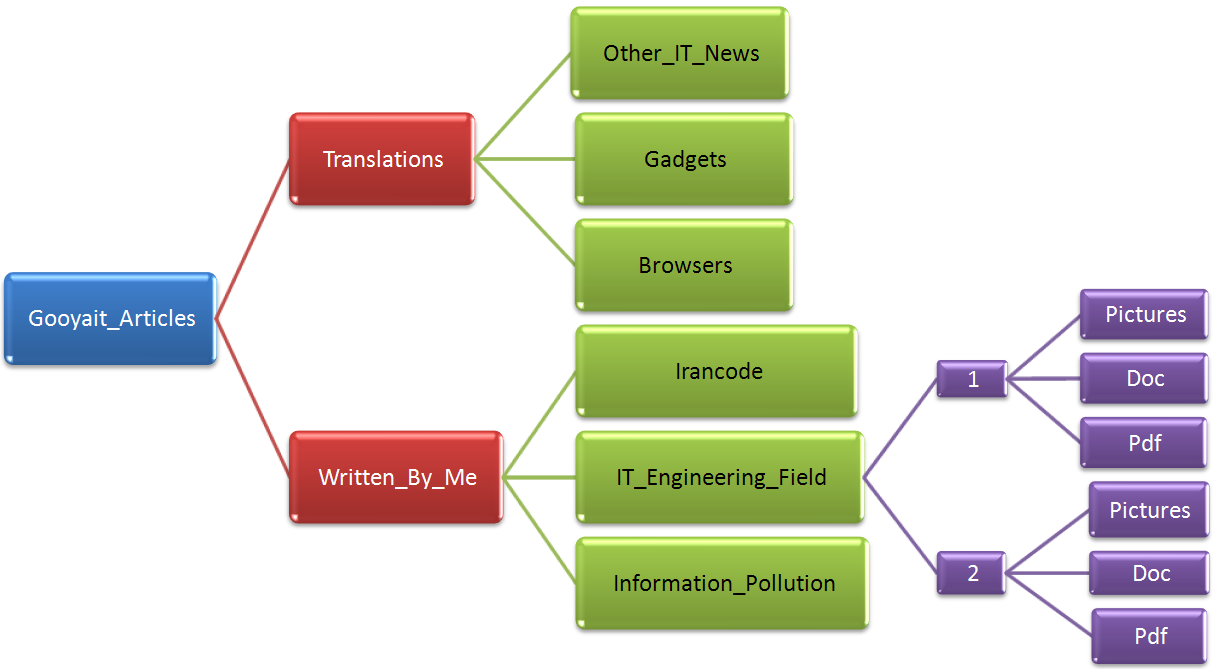
روشهاي ذكر شده، كمك ميكنند كه به اندازهي قابل توجهي از آلودگي اطلاعات جلوگيري كنيم. در ادامه روشي براي از بين بردن آلودگي اطلاعات در سازمان معرفي خواهد شد.
راهكاري مناسب براي رفع آلودگي اطّلاعات
حال نمونهاي از برطرف كردن آلودگي اطّلاعات از نوع فايلهاي تكراري را مورد بررسي قرار خواهيم داد. به اين علت كه بيشتر سر و كار ارگانها و سازمانها با فايلهاي متني است، فرض ميكنيم دو فايل از نوع متن وجود دارند كه از نظر محتوايي با هم يكسان هستند امّا نامهاي متفاوت دارند ور در مكانهاي مختلفي در سيستم كپي شدهاند. سيستم عاملهاي كنوني نميتوانند يكسان بودن اين دو فايل را تشخيص دهند. ما بنا داريم سيستم را جستجو كرده و فايلهاي مشابه را كه در چند جاي سيستم كپي شدهاند شناسايي كرده و نسخه هاي اضافي را حذف كنيم. به نظر ميرسد اين كار تا حد زيادي سخت و ناكارآمد باشد. دقيقا به همين دليل است كه پيشتر در همين مطلب بيان كرديم كه پيشگيري بهتر از درمان است!
امروزه نرمافزارهايي وجود دارند كه محتواي دو فايل را با هم مقايسه كرده و يكسان بودن يا نبودن آنها را مشخص ميكنند. نمونه اي از اين نرمافزارها با نام WinDiff كه محصول شركت مايكروسافت به شمار ميرود از سال 1992 تا كنون به عنوان يكي از كامپوننتهاي ويندوز قابل نصب بوده است. اين نرمافزار كم حجم از سايت شركت مايكروسافت قابل بارگذاري است و البته با نصب Service Pack 2 ويندوز XP به طور خودكار نصب ميشود. گرچه معمولاً كارايي اين نرمافزار دقيق و كارآمد است، امّا در صورت كمي تغيير در محتواي فايلها در فرايند جستجوي آنها، نرمافزار به مشكل بر ميخورد چون الگوريتم بررسي محتواي اين نرمافزار به مقايسهي بيت به بيت فايلها ميپردازد و عبارات موجود در محتوا را مورد بررسي قرار نميدهد. مثلاً اگر فونت يك مقاله را تغيير دهيم، متأسفانه نرمافزار مذكور، دو فايل را متفاوت ميشناسد در صورتي كه اين دو فايل از جهت محتوا يكسان هستند.
با كليك بر روي تصوير زير به صفحهاي از وبسايت شركت مايكروسافت منتقل ميشويد كه مربوط به دانلود بستهي نرمافزارهاي كمكي ويندوز با حجم 4.7 مگابايت است. windiff هم به عنوان يكي از نرمافزارهاي اين بسته داخل آن گنجانده شده است.

Windiff را به همراه كدهاي منبع آن به صورت مستقل مي توانيد از آدرسهاي زير دانلود نماييد:
http://www.codeproject.com/KB/applications/runwindiff.aspx
http://www.grigsoft.com/download-windiff.htm
البته به غير از windiff نرمافزارهاي ديگري نيز با كاركردهاي متفاوت و الگوريتمهاي جستجو و مقايسهي متنوع وجود دارند كه از طريق آدرس زير ميتوانيد آنها را به صورت تخصصي و مفصل با هم مقايسه نماييد.
http://en.wikipedia.org/wiki/Comparison_of_file_comparison_tools
از بين نرمافزارهاي موجود در ليست بالا، دو نرمافزار Beyond Compare و WinMerge شناخته شدهتر هستند و رابط كاربري بهتري دارند. در ادامهي مطلب به معرفي اين دو نرمافزار، نحوهي كار آنها و اطلاعات تكميلي در مورد مقايسهي محتواي دو فايل خواهيم پرداخت. در تمام طول نوشته سعي بر اين است كه مخاطب درگير پيچيدگيهاي ساختاري و نرمافزاري نباشد و فقط با نحوهي كار اين نرمافزارها آشنا شود. به همين دليل به بررسي چگونگي عملكرد فني اين نرم افزارها نميپردازيم.
معمولترين شيوهي بررسي و مقايسهي دو فايل:
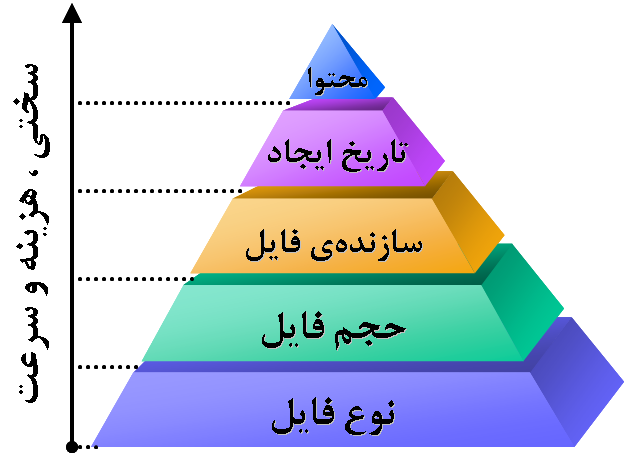
- اوّلين مرحله براي تشخيص يكسان بودن دو فايل، تشخيص يكسان بودن نوع آن فايلهاست. واضح است كه يك فايل متني و يك فايل صوتي هيچگاه نميتوانند با هم يكسان باشند (گرچه ممكن است پيامي مشترك را انتقال دهند امّا دو رسانه از دو نوع متفاوتند). بنابراين در اوّلين قدم، پسوند نام دو فايل را مورد بررسي قرار ميدهيم و تمامي فايلهاي مورد بررسي را در پوشههايي بر اساس نوع فايل، دستهبندي ميكنيم.
- قدم بعدي، تشخيص يكسان بودن حجم دو فايل است. البتّه نميتوان مطلقاً بيان كرد كه دو فايل با حجم متفاوت ( منظور اصلي فايلهاي از نوع متني است ) با هم يكسان يا متفاوتند. امّا با درصد خطاي قابل قبولي ميتوان به نتايجي مناسب رسيد. در اين مرحله نيز فايلهايي كه همنوع هستند، به جهت حجم، بررسي و به پوشههايي با معيار طبقهبندي بر اساس حجم، دستهبندي ميشوند. نقص موجود در اين مرحله را ميتوان با اجراي مراحل بعدي برطرف كرد كه در ادامه به آنها خواهيم پرداخت.
- پس از اين مرحله، به اينكه هر فايل توسّط چه كسي و بر اساس چه ليسانسي تهيّه شدهاست ميپردازيم. فايلهايي كه توسّط برنامههاي مختلف توليد فايل متني ايجاد ميشوند، مشخّصات مربوط به سازندهي خود، اعم از نام رايانه، نام كاربري و … را در خود ذخيره ميكنند. بنابراين، سازندهي فايل نيز ميتواند به عنوان فيلتري براي تشخيص يكسان بودن دو فايل به كار رود.
- مرحلهي بعدي، تاريخ ايجاد فايل است. در واقع طبقهبندي فايلها بر اساس تاريخ ايجاد نيز ممكن است تا حدي به جستجو و دريافت نتايج بهتر و سريعتر كمك نمايد.
- در آخرين مرحله و در صورتي كه تا به اين مرحله، تصميمي قاطع در مورد محتواي دو فايل گرفته نشده باشد، همانند نقصي كه در مرحلهي حجم وجود داشت، ميتوان با استفاده از الگوريتمهايي هوشمند، محتواي دو فايل را جستجو و يكسان بودن آن فايلها را متوجّه شد. اين الگوريتمها بايد به اندازهي كافي دقيق و سريع باشند تا ما را مجاب به استفاده از اين روش به جاي روش مقايسهي بيت به بيت كرده و جواب مناسبي ارائه دهند. به عنوان يك الگوريتم خوب و بهينه در اين مورد، ميتوان به جاي چك كردن كل محتواي دو فايل، به اين نكته توجّه كرد كه اگر لغت يا عبارتي در يك فايل وجود داشت و در فايل ديگر موجود نبود، يعني اين دو فايل يكسان نيستند و با استفاده از اين آگاهي، شروع به انتخاب تصادفي كلماتي از يك فايل (مثلا 50 كلمه) و جستجوي آنها در فايل ديگر نمود كه اين نيز روشهاي كنترلي خاص خود را ميطلبد.
مراحل ذكر شده را به طور شماتيك در شكل زير ملاحظه ميفرماييد:
شيوهي معمول كار اينگونه نرمافزارها بدين صورت است كه كاربر ابتدا نرمافزار را اجرا ميكند. نرمافزار در پسزمينه و بصورت خاموش[11] شروع به كار ميكند. كاربر مكان فايلهايي كه قرار است بررسي شوند را به نرمافزار ميدهد. سپس نرمافزار بر طبق متدلوژي خاص خود، آن فايلها را با هم مقايسه و پس از ارائهي نتايج، به خواست كاربر فايلهاي تكراري را پاك ميكند.
در ابتدا ممكن است اين كار، غير ضروري و منافع آن براي ما اندك به نظر برسد، امّا در سيستمهاي اطّلاعاتي بزرگ (جوامع اطّلاعاتي) با حجم و تعداد انبوهي از فايلها، اين كار نتايج مثبت قابل قبولي را ارائه ميكند. برخي از مزاياي اين كار عبارتند از:
- حذف فايلهاي يكسان و رهاسازي فضاي اشغال شده در سيستم
- دستهبندي فايلهاي مشابه با انواع مختلفي از گروهبنديهاي حجمي و پسوندي و تاريخ ايجاد و …
- حذف فايلهاي بياستفاده و قديمي
- شناخت سيستم پاكسازي شده كه به نوعي آمارگيري كلّي از سيستم نيز منتهي ميشود.
- و مزاياي بيشمار ديگر …
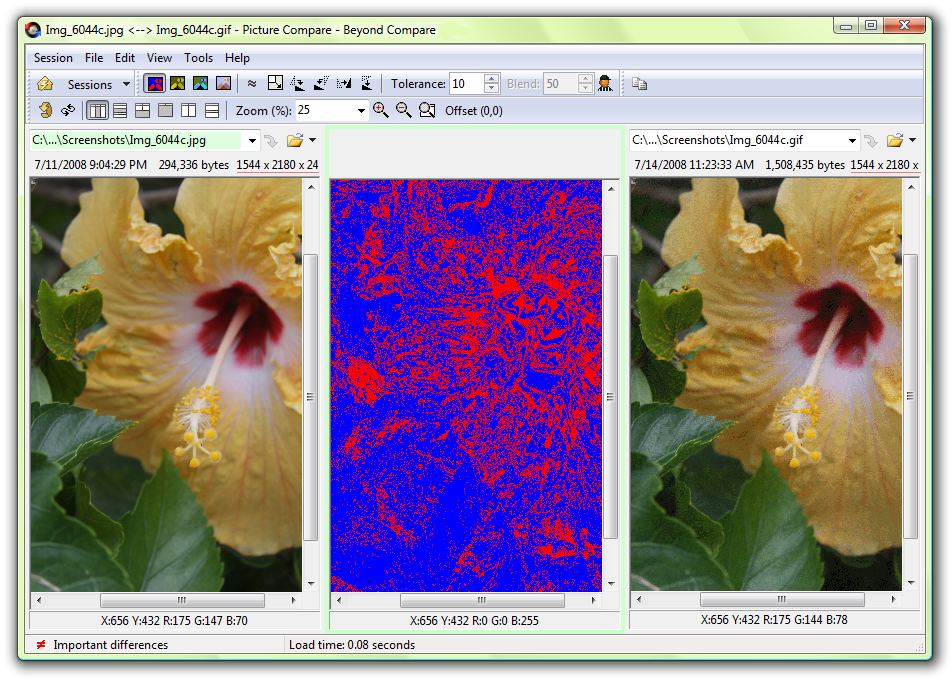
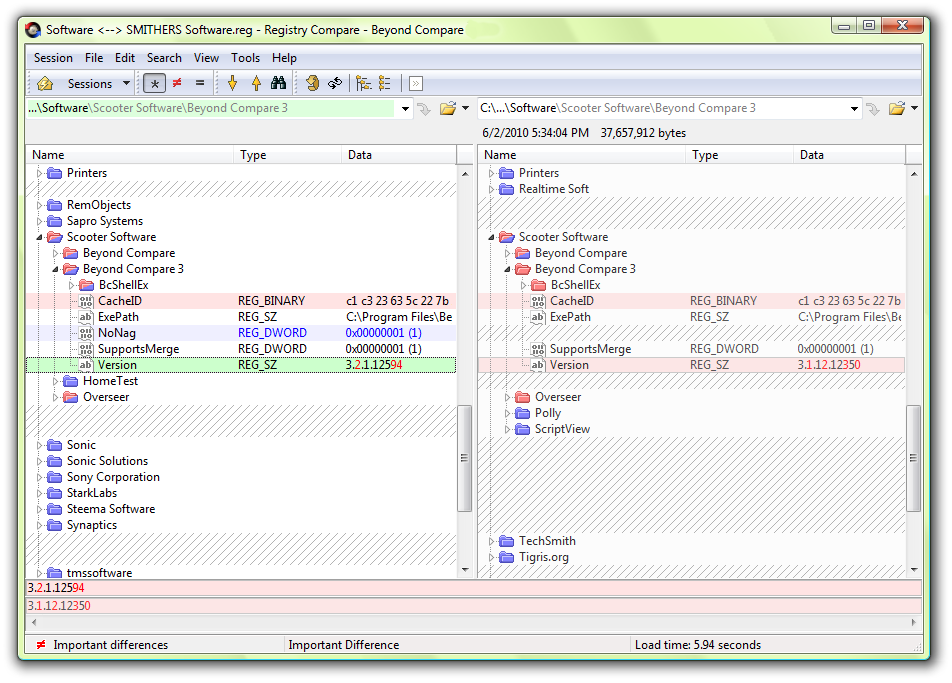
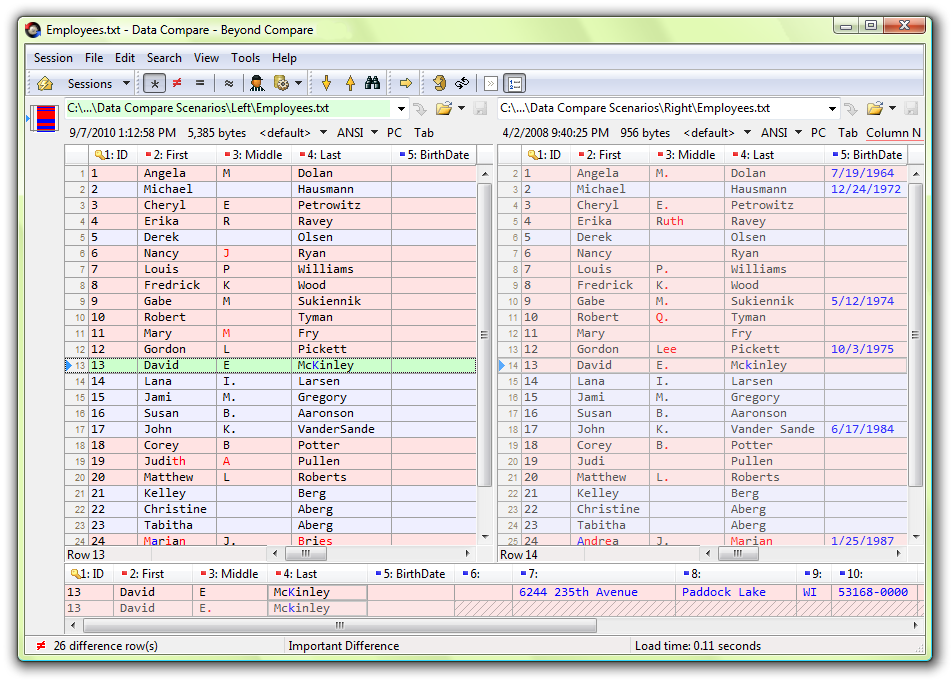
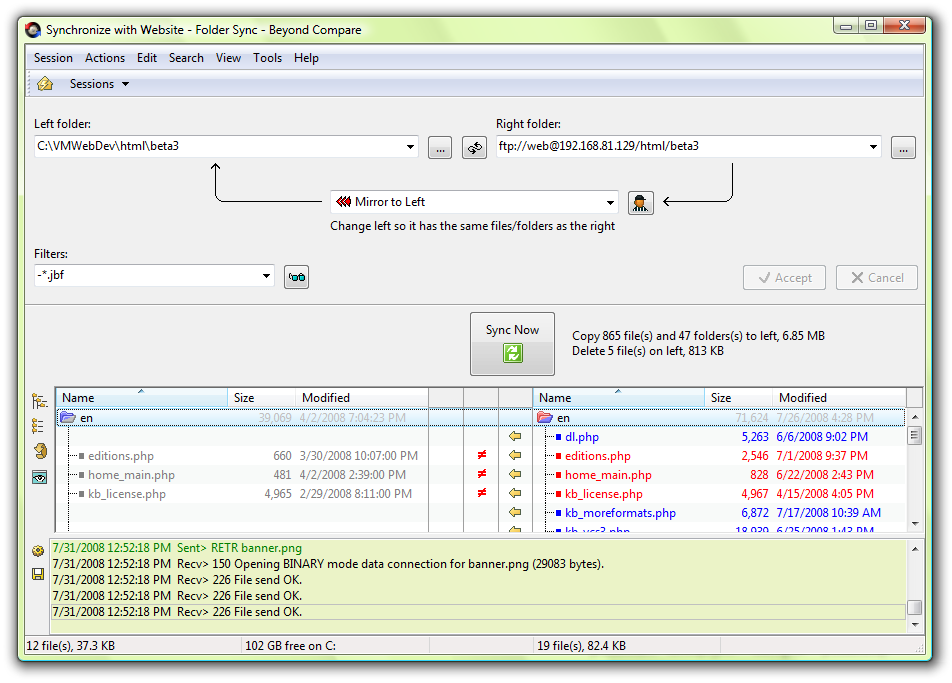
معرفي نرمافزار Beyond Compare
نرمافزار نامبرده يكي از قويترين نرم افزارهاي موجود در زمينهي مقايسهي انواع فايل ها است. با مراجعه به وبسايت رسمي اين نرمافزار ميتوانيد اطلاعات بسيار كاملي از جمله تصاوير، ويديوهاي آموزشي، متون راهنما و … در مورد آن پيدا كنيد.
برخي از ويژگي هاي اين نرمافزار عبارتند از:
- پشتيباني كامل از محتوا و نام فايلهاي Unicode
- مقايسهي محتويات دو يا چند پوشه
- مقايسهي محتواي فايلها با پسوندهاي مختلف
- پشتيباني از tab ها براي مرور بهتر نتايج مقايسه
- امكان تعيين اقدامات مشخص پس از مقايسهي دو فايل (حذف، تركيب، كپي، جايگزيني و …)
- و …
توسط اين نرم افزار ميتوانيد فايل هاي Excel، word، PDF، انواع مختلف فايل هاي متني ديگر، انواع مختلف فايلهاي عكس، فايلهاي صوتي، فايل هاي ويديويي، فايلهاي رجيستري، فايلهاي اجرايي، پوشهها و … را با هم مقايسه نماييد. در ادامه تعدادي از screenshot هاي مربوط به اين نرمافزار را ميبينيم.
معرفي نرمافزار WinMerge
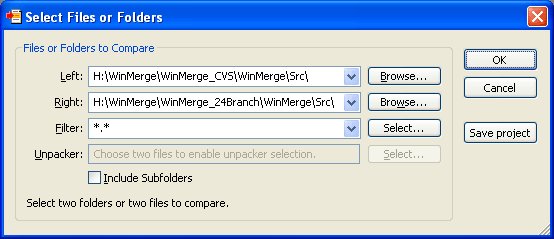
اين نرمافزار از لحاظ ساختاري با Windiff شباهت بسياري دارد. اما محيط كاربري و امكانات آن كاربر پسندتر است. با مراجعه به وبسايت رسمي اين نرمافزار نيز اطلاعات خوبي در مورد ان خواهيد يافت.
برخي از مهمترين ويژگيهاي اين نرمافزار عبارتند از:
- پشتيباني از زبان هاي مختلف و كاراكترهاي Unicode
- امكان مقايسهي فايل هاي متني و امكان تعيين اقدامات مشخص پس از مقايسهي فايلها (حذف، تركيب، كپي، جايگزيني و …)
- امكان توليد گزارشات HTML از نتايج مقايسه
- امكان مقايسهي چند پوشه
- پشتيباني كامل از انواع فايلهاي ويندوزي
- و …
در ادامه چند screenshot از اين نرمافزار را ميبينيم.
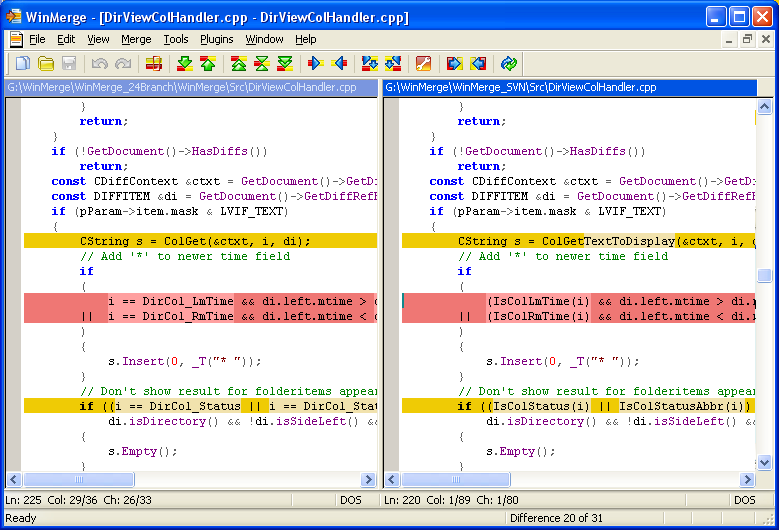
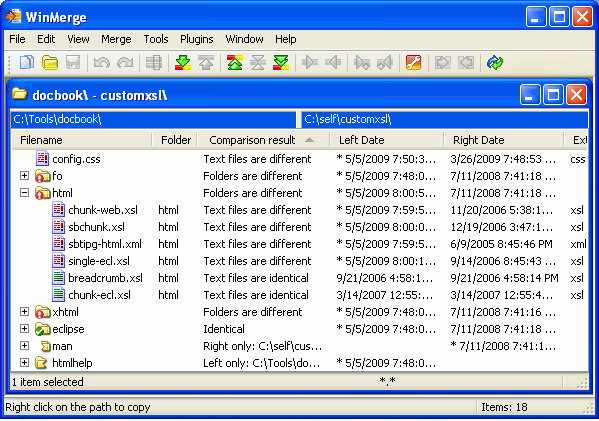
نتيجهگيري
بنابر آنچه كه گفته شد، آلودگي اطّلاعات پديدهاي است كه در جوامع اطّلاعاتي در حال گسترش بوده و هر روز، بيش از روز قبل براي صاحبان و كاربران سيستم مشكلزا ميشود. به همين دليل بايد از وقوع آن جلوگيري و يا در صورت رخداد آن را از بين برد.
مطلبي كه در خاتمه بايد به آن اشارهكرد، كاربردهاي اين روش در سيستمهاي اطّلاعاتي است. از اين روش ميتوان در سيستمهاي پشتيباني از تصميمگيري، سيستمهاي دادهكاوي و دادهپردازي، موتورهاي جستجو، سيستمهاي خبره، سيستمهاي مبتني بر هوش مصنوعي، سيستمهاي مديريت فنّاوري اطّلاعات، سيستمهاي جامع درون سازماني، رايانههاي شخصي، اجتماعات مجازي و شبكههاي تحت وب و بخشهاي بسيار ديگر استفاده كرد.
از اين مطلب ميتوان براي گسترش تحقيق در موضوعاتي همچون پايگاههاي دادهي هوشمند، بيماريهاي اطّلاعاتي، دادهكاوي و دادهپردازي، سيستمهاي اطّلاعاتي بهينه و … استفاده كرد. در نهايت، جواب تمامي اين تحقيقات، منجر به پيشرفت صنعت رايانه در توليد، نگهداري، پردازش، انتقال و امنيّت اطّلاعات و ديگر موضوعات مربوط به دنياي رايانه و فنّاوري اطّلاعات خواهد شد.
محسن پاك نيت
پاورقي
[1] Prevention
[2] Elimination
[3] Guideline
[4] Backup Server
[5] Separator
[6] Space Key
[7] Dash
[8] Hyphen
[9] Underline
[10] Version Number
[11] Silent
سلام محسن
مطلب خوبی بود اما یک نظری داشتم این هست که سعی بکن خیلی خلاصه وار و کم متن قراب بده خودم به شخصه اگر مطلبی طولانی ببنیم چند ختش بیشتر نیمخونم و یا اینکه اصلا نمیخونم و یا سعی بکن در چندین قسمت کوتاه مقالت قرار بده که خواننده خسته نشه
همیشه سربلند موفق باشید…
سلام ناصر عزیز.
چشم گل پسر. این مورد رو سعی می کنم رعایت کنم. البته این نوشته از اون جنس نوشته هایی هستش که خواننده های خاص خودش رو داره و درصد کمی از افراد می خوننش. اما همونایی که می خونن هم کامل می خونن. چون فقط کسی دنبال اینجور مطالب میاد که واقعا بهشسون نیاز داره و دنبالشون می گرده.
اما به هر حال پیشنهادت عالیه. مرسی.
شما هم همیشه سربلند و سلامت باشی.