





مقدمه:
اگر مباحث قسمت اول از این مطلب را مطالعه کرده باشید، مفهوم آلودگی اطلاعات را به خوبی میشناسید. در ادامه قصد داریم راهکارهای مواجه شدن با آلودگی اطلاعات را مورد بررسی قرار دهیم. لطفا با مجله اینترنتی گویا آیتی همراه باشید.
مواجهه با آلودگی اطّلاعات
دو راهکار پیشگیری [۱] و برطرف کردن [۲] را میتوان برای مواجهه با آلودگی اطّلاعات در نظر گرفت:
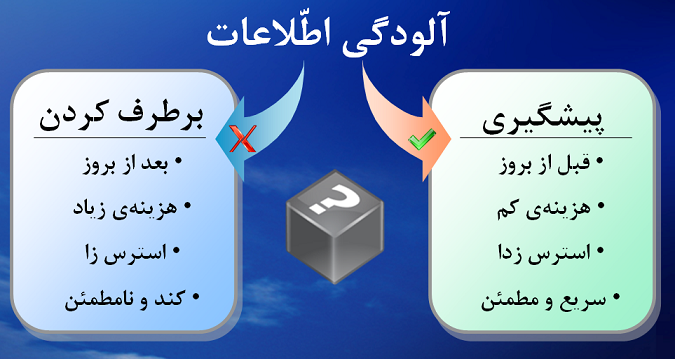
دو راهکار مواجهه با آلودگی اطلاعات
جدول ۱: پیشگیری و برطرفکردن آلودگی اطلاعات
پیشگیری :
|
بر طرف کردن :
|
راهکاری مناسب برای پیشگیری از آلودگی اطّلاعات
بهترین روش برای پیشگیری از رخداد آلودگی اطلاعات در سازمان (یا در رایانهی شخصی) این است که دادههای ورودی به رایانه (فایلها، رکوردهای بانک اطلاعاتی و …) را به دقت کنترل کنیم. قبل از این کار، لازم است استانداردها و قواعدی تعریف کنیم که بر اساس این استانداردها دادهها به سیستم مورد نظر ورود پیدا کنند و هیچ دادهای بدون در نظر گرفتن این قواعد وارد سیستم نشود. این روش را طی چند گام با هم مرور میکنیم:
- دانش سازمان خود را بالا ببرید: به این مفهوم که با آموزش مطالب روز در مورد حیطهی کاری سازمانی که مدیریت آنرا بر عهده دارید، کارمندان خود را به روز نگه دارید. کارمندانی که به روز هستند کمک بزرگی به سازمان در تشخیص اطلاعات به درد بخور از اطلاعات به درد نخور میکنند.
- به افرادی که با سیستم شما در تماس هستند آموزش بدهید: با تهیهی راهنماها[۳] و دستورالعملهای مربوط به نامگذاری و آرشیو و رد و بدل کردن دادهها در سازمان، به افرادی که با سیستم سر و کار دارند بیاموزید که دادههای به درد نخور را حذف کنند. دادههای قدیمی را ویرایش و به روز کرده و نسخههای پیشین را از گردش کاری حذف کنند. (مگر اینکه سیاست سازمان بر این باشد که تمام نسخههای مستندات را ذخیره بایگانی کند) به کاربران و کارمندان بیاموزید که نسخههای کپی مختلف از یک فایل ایجاد نکنند. برخی افراد عادت دارند نسخههای مختلفی از فایلها را در درایوهای مختلف هارد دیسک ذخیره کنند که در صورت از بین رفتن فایل، نسخهی پشتیبان داشته باشند. این کار لازم نیست. به جای آن سرور پشتیبان[۴] راه اندازی کنید.
- نرمافزار ضد ویروس مطمئن خریداری کنید و آن را همیشه به روز نگه دارید: اطلاعات یکی از مهمترین داراییهای سازمان است. اگر دزدیده شود، اگر از بین برود، اگر مخدوش شود، ضرری که ایجاد میشود تقریبا غیر قابل جبران است. اگر سختافزار تخریب شود، میتوان آن را مجددا خریداری کرد. اما اطلاعاتی که توسط شما تولید شده باشد، در صورت از بین رفتن، در جای دیگری وجود ندارد که بخواهید آن را مجدد خریداری کنید.
- از تکنیکهای نامگذاری استاندارد برای ذخیرهی فایلها استفاده کنید: فایلها را با زبان انگلیسی درون سیستم ذخیره کنید. نامهایی که از چند کلمه تشکیل شدهاند را توسط یک نوع جداکننده[۵] ثابت یادداشت کنید. اینطور نباشد که اسامی برخی فایلها با کلید فاصله[۶]، برخی دیگر با خط تیره[۷] ، برخی با خط ربط[۸] و برخی دیگر با زیرخط[۹] از هم جدا شده باشند. این کار جستجوی اطلاعات را نیز سادهتر میکند. اگر در اسمگذاری فایلها، کوچک و بزرگ بودن حروف برایتان مهم است، همهجا این قاعده را به طور یکشکل رعایت کنید. اگر چند فایل مرتبط به هم دارید، مثلا ۲ تصویر از لوگوی سایت گویا آیتی، آنها را به طور مشابه و با شمارهگذاری تعیین نام کنید. مثلا: Gooyait_Logo_1.jpg و Gooyait_Logo_2.gif
- یک ساختار شمارهگذاری برای تشخیص نسخههای مختلف فایلها ایجاد کنید و به آن پایبند باشید. مثلا میتوانید تاریخ تولید یک فایل را نیز در نام آن بیاورید. یا مثلا شماره نسخه [۱۰] به نسخههای متعدد یک فایل اختصاص دهید.
- برای دستهبندی انواع مختلف فایلها از پوشهها استفاده کنید. سعی کنید تا جای ممکن انواع فایلهای مختلف را درون یک پوشه در کنار هم نداشته باشید. مثلا میتوانید ساختار پوشهبندی را اینگونه ایجاد کنید:
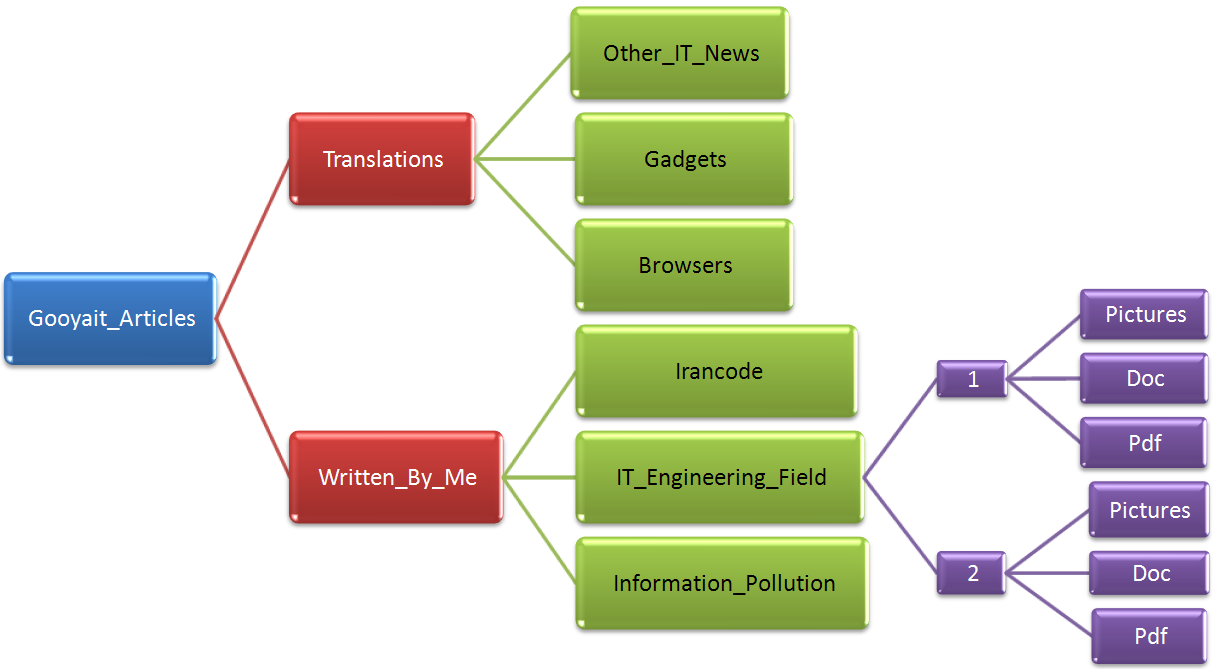
دستهبندی فایلها و پوشهها به شیوهی استانداردی که توسط خود شما تعریف شده است
روشهای ذکر شده، کمک میکنند که به اندازهی قابل توجهی از آلودگی اطلاعات جلوگیری کنیم. در ادامه روشی برای از بین بردن آلودگی اطلاعات در سازمان معرفی خواهد شد.
راهکاری مناسب برای رفع آلودگی اطّلاعات
حال نمونهای از برطرف کردن آلودگی اطّلاعات از نوع فایلهای تکراری را مورد بررسی قرار خواهیم داد. به این علت که بیشتر سر و کار ارگانها و سازمانها با فایلهای متنی است، فرض میکنیم دو فایل از نوع متن وجود دارند که از نظر محتوایی با هم یکسان هستند امّا نامهای متفاوت دارند ور در مکانهای مختلفی در سیستم کپی شدهاند. سیستم عاملهای کنونی نمیتوانند یکسان بودن این دو فایل را تشخیص دهند. ما بنا داریم سیستم را جستجو کرده و فایلهای مشابه را که در چند جای سیستم کپی شدهاند شناسایی کرده و نسخه های اضافی را حذف کنیم. به نظر میرسد این کار تا حد زیادی سخت و ناکارآمد باشد. دقیقا به همین دلیل است که پیشتر در همین مطلب بیان کردیم که پیشگیری بهتر از درمان است!
امروزه نرمافزارهایی وجود دارند که محتوای دو فایل را با هم مقایسه کرده و یکسان بودن یا نبودن آنها را مشخص میکنند. نمونه ای از این نرمافزارها با نام WinDiff که محصول شرکت مایکروسافت به شمار میرود از سال ۱۹۹۲ تا کنون به عنوان یکی از کامپوننتهای ویندوز قابل نصب بوده است. این نرمافزار کم حجم از سایت شرکت مایکروسافت قابل بارگذاری است و البته با نصب Service Pack 2 ویندوز XP به طور خودکار نصب میشود. گرچه معمولاً کارایی این نرمافزار دقیق و کارآمد است، امّا در صورت کمی تغییر در محتوای فایلها در فرایند جستجوی آنها، نرمافزار به مشکل بر میخورد چون الگوریتم بررسی محتوای این نرمافزار به مقایسهی بیت به بیت فایلها میپردازد و عبارات موجود در محتوا را مورد بررسی قرار نمیدهد. مثلاً اگر فونت یک مقاله را تغییر دهیم، متأسفانه نرمافزار مذکور، دو فایل را متفاوت میشناسد در صورتی که این دو فایل از جهت محتوا یکسان هستند.
با کلیک بر روی تصویر زیر به صفحهای از وبسایت شرکت مایکروسافت منتقل میشوید که مربوط به دانلود بستهی نرمافزارهای کمکی ویندوز با حجم ۴.۷ مگابایت است. windiff هم به عنوان یکی از نرمافزارهای این بسته داخل آن گنجانده شده است.
کلیک کنید
Windiff را به همراه کدهای منبع آن به صورت مستقل می توانید از آدرسهای زیر دانلود نمایید:
http://www.codeproject.com/KB/applications/runwindiff.aspx
http://www.grigsoft.com/download-windiff.htm
البته به غیر از windiff نرمافزارهای دیگری نیز با کارکردهای متفاوت و الگوریتمهای جستجو و مقایسهی متنوع وجود دارند که از طریق آدرس زیر میتوانید آنها را به صورت تخصصی و مفصل با هم مقایسه نمایید.
http://en.wikipedia.org/wiki/Comparison_of_file_comparison_tools
از بین نرمافزارهای موجود در لیست بالا، دو نرمافزار Beyond Compare و WinMerge شناخته شدهتر هستند و رابط کاربری بهتری دارند. در ادامهی مطلب به معرفی این دو نرمافزار، نحوهی کار آنها و اطلاعات تکمیلی در مورد مقایسهی محتوای دو فایل خواهیم پرداخت. در تمام طول نوشته سعی بر این است که مخاطب درگیر پیچیدگیهای ساختاری و نرمافزاری نباشد و فقط با نحوهی کار این نرمافزارها آشنا شود. به همین دلیل به بررسی چگونگی عملکرد فنی این نرم افزارها نمیپردازیم.
معمولترین شیوهی بررسی و مقایسهی دو فایل:
- اوّلین مرحله برای تشخیص یکسان بودن دو فایل، تشخیص یکسان بودن نوع آن فایلهاست. واضح است که یک فایل متنی و یک فایل صوتی هیچگاه نمیتوانند با هم یکسان باشند (گرچه ممکن است پیامی مشترک را انتقال دهند امّا دو رسانه از دو نوع متفاوتند). بنابراین در اوّلین قدم، پسوند نام دو فایل را مورد بررسی قرار میدهیم و تمامی فایلهای مورد بررسی را در پوشههایی بر اساس نوع فایل، دستهبندی میکنیم.
- قدم بعدی، تشخیص یکسان بودن حجم دو فایل است. البتّه نمیتوان مطلقاً بیان کرد که دو فایل با حجم متفاوت ( منظور اصلی فایلهای از نوع متنی است ) با هم یکسان یا متفاوتند. امّا با درصد خطای قابل قبولی میتوان به نتایجی مناسب رسید. در این مرحله نیز فایلهایی که همنوع هستند، به جهت حجم، بررسی و به پوشههایی با معیار طبقهبندی بر اساس حجم، دستهبندی میشوند. نقص موجود در این مرحله را میتوان با اجرای مراحل بعدی برطرف کرد که در ادامه به آنها خواهیم پرداخت.
- پس از این مرحله، به اینکه هر فایل توسّط چه کسی و بر اساس چه لیسانسی تهیّه شدهاست میپردازیم. فایلهایی که توسّط برنامههای مختلف تولید فایل متنی ایجاد میشوند، مشخّصات مربوط به سازندهی خود، اعم از نام رایانه، نام کاربری و … را در خود ذخیره میکنند. بنابراین، سازندهی فایل نیز میتواند به عنوان فیلتری برای تشخیص یکسان بودن دو فایل به کار رود.
- مرحلهی بعدی، تاریخ ایجاد فایل است. در واقع طبقهبندی فایلها بر اساس تاریخ ایجاد نیز ممکن است تا حدی به جستجو و دریافت نتایج بهتر و سریعتر کمک نماید.
- در آخرین مرحله و در صورتی که تا به این مرحله، تصمیمی قاطع در مورد محتوای دو فایل گرفته نشده باشد، همانند نقصی که در مرحلهی حجم وجود داشت، میتوان با استفاده از الگوریتمهایی هوشمند، محتوای دو فایل را جستجو و یکسان بودن آن فایلها را متوجّه شد. این الگوریتمها باید به اندازهی کافی دقیق و سریع باشند تا ما را مجاب به استفاده از این روش به جای روش مقایسهی بیت به بیت کرده و جواب مناسبی ارائه دهند. به عنوان یک الگوریتم خوب و بهینه در این مورد، میتوان به جای چک کردن کل محتوای دو فایل، به این نکته توجّه کرد که اگر لغت یا عبارتی در یک فایل وجود داشت و در فایل دیگر موجود نبود، یعنی این دو فایل یکسان نیستند و با استفاده از این آگاهی، شروع به انتخاب تصادفی کلماتی از یک فایل (مثلا ۵۰ کلمه) و جستجوی آنها در فایل دیگر نمود که این نیز روشهای کنترلی خاص خود را میطلبد.
مراحل ذکر شده را به طور شماتیک در شکل زیر ملاحظه میفرمایید:
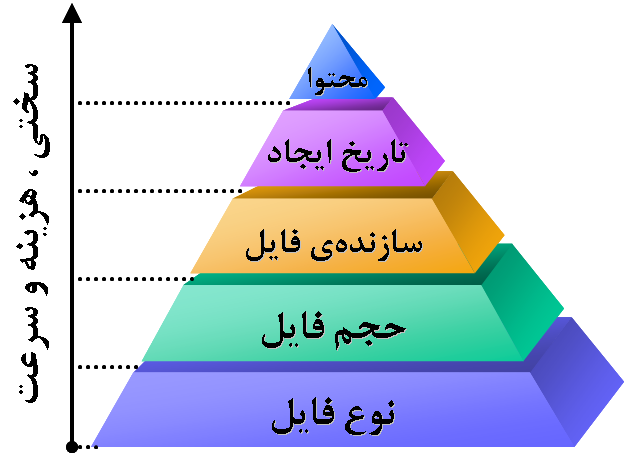
هرم بررسی دو فایل
شیوهی معمول کار اینگونه نرمافزارها بدین صورت است که کاربر ابتدا نرمافزار را اجرا میکند. نرمافزار در پسزمینه و بصورت خاموش[۱۱] شروع به کار میکند. کاربر مکان فایلهایی که قرار است بررسی شوند را به نرمافزار میدهد. سپس نرمافزار بر طبق متدلوژی خاص خود، آن فایلها را با هم مقایسه و پس از ارائهی نتایج، به خواست کاربر فایلهای تکراری را پاک میکند.
در ابتدا ممکن است این کار، غیر ضروری و منافع آن برای ما اندک به نظر برسد، امّا در سیستمهای اطّلاعاتی بزرگ (جوامع اطّلاعاتی) با حجم و تعداد انبوهی از فایلها، این کار نتایج مثبت قابل قبولی را ارائه میکند. برخی از مزایای این کار عبارتند از:
- حذف فایلهای یکسان و رهاسازی فضای اشغال شده در سیستم
- دستهبندی فایلهای مشابه با انواع مختلفی از گروهبندیهای حجمی و پسوندی و تاریخ ایجاد و …
- حذف فایلهای بیاستفاده و قدیمی
- شناخت سیستم پاکسازی شده که به نوعی آمارگیری کلّی از سیستم نیز منتهی میشود.
- و مزایای بیشمار دیگر …
معرفی نرمافزار Beyond Compare
نرمافزار نامبرده یکی از قویترین نرم افزارهای موجود در زمینهی مقایسهی انواع فایل ها است. با مراجعه به وبسایت رسمی این نرمافزار میتوانید اطلاعات بسیار کاملی از جمله تصاویر، ویدیوهای آموزشی، متون راهنما و … در مورد آن پیدا کنید.
برخی از ویژگی های این نرمافزار عبارتند از:
- پشتیبانی کامل از محتوا و نام فایلهای Unicode
- مقایسهی محتویات دو یا چند پوشه
- مقایسهی محتوای فایلها با پسوندهای مختلف
- پشتیبانی از tab ها برای مرور بهتر نتایج مقایسه
- امکان تعیین اقدامات مشخص پس از مقایسهی دو فایل (حذف، ترکیب، کپی، جایگزینی و …)
- و …
توسط این نرم افزار میتوانید فایل های Excel، word، PDF، انواع مختلف فایل های متنی دیگر، انواع مختلف فایلهای عکس، فایلهای صوتی، فایل های ویدیویی، فایلهای رجیستری، فایلهای اجرایی، پوشهها و … را با هم مقایسه نمایید. در ادامه تعدادی از screenshot های مربوط به این نرمافزار را میبینیم.
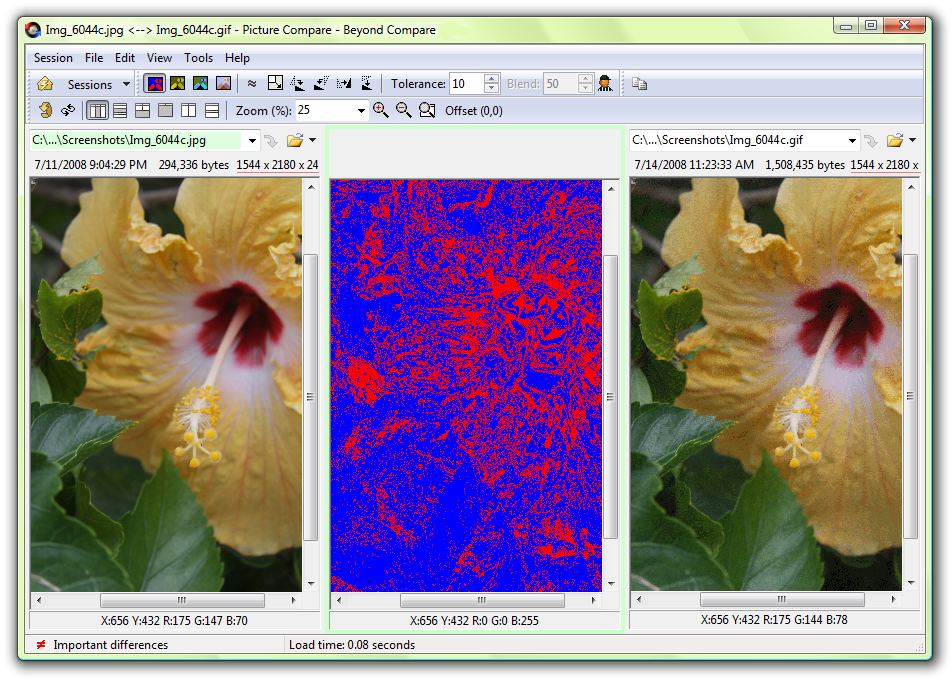
مقایسهی تصاویر
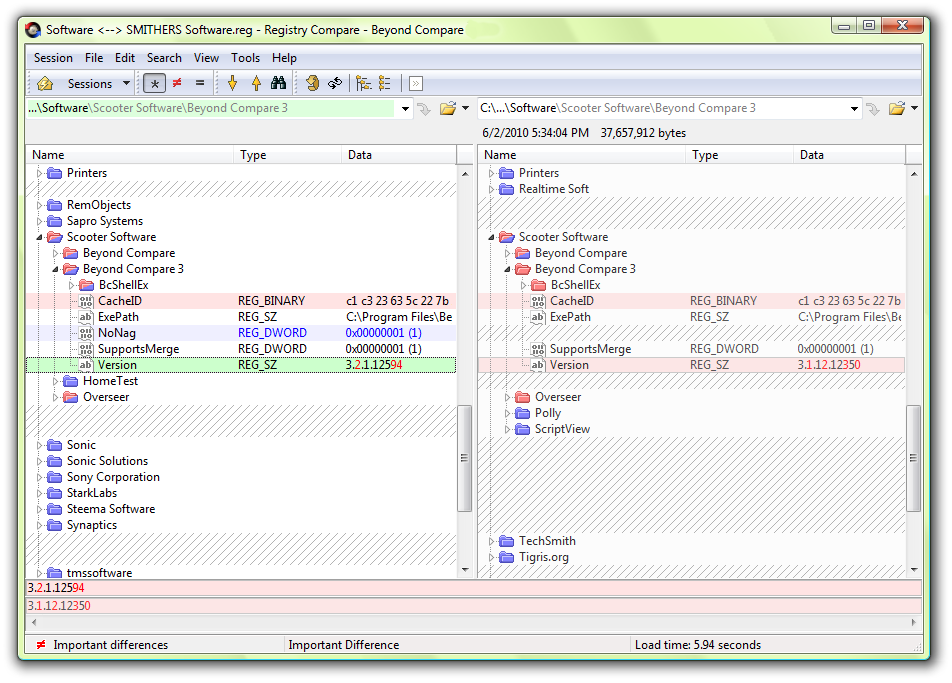
مقایسهی کلیدهای رجیستری
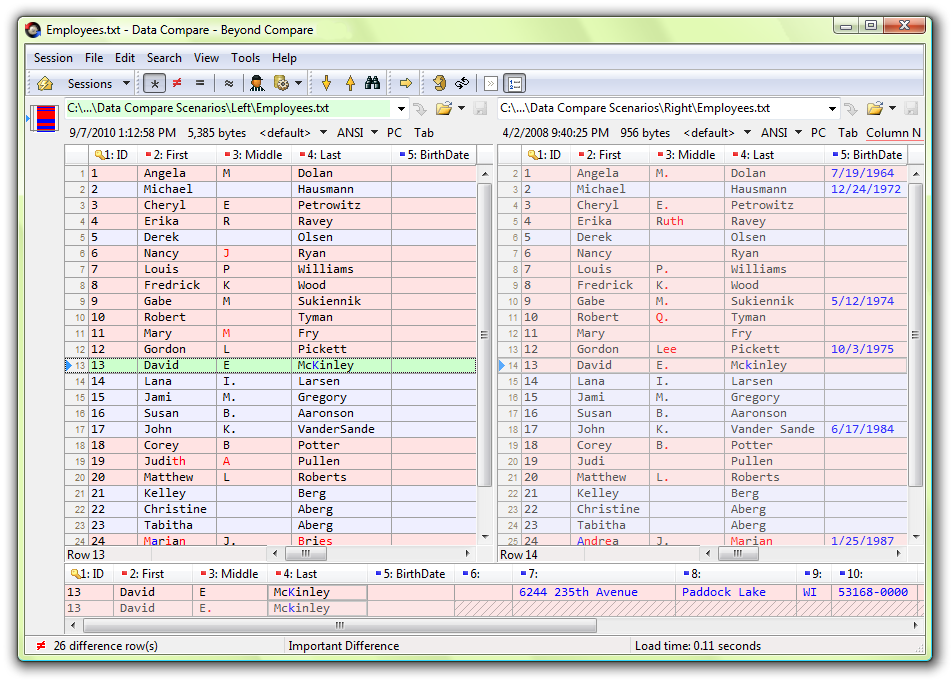
مقایسهی دو فایل متنی (جدول)
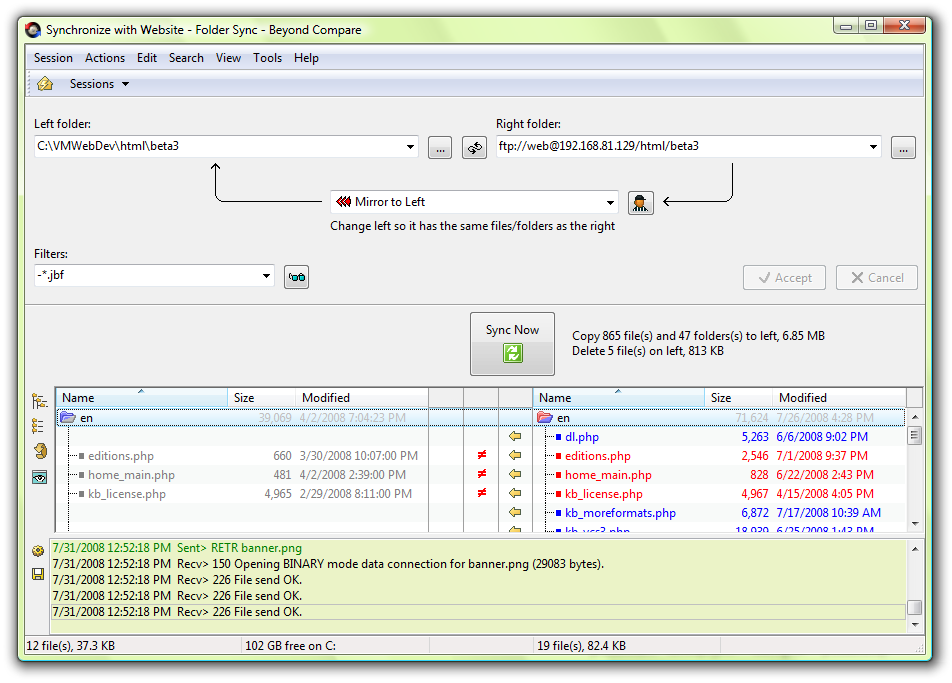
مقایسهی محتویات دو پوشه
معرفی نرمافزار WinMerge
این نرمافزار از لحاظ ساختاری با Windiff شباهت بسیاری دارد. اما محیط کاربری و امکانات آن کاربر پسندتر است. با مراجعه به وبسایت رسمی این نرمافزار نیز اطلاعات خوبی در مورد ان خواهید یافت.
برخی از مهمترین ویژگیهای این نرمافزار عبارتند از:
- پشتیبانی از زبان های مختلف و کاراکترهای Unicode
- امکان مقایسهی فایل های متنی و امکان تعیین اقدامات مشخص پس از مقایسهی فایلها (حذف، ترکیب، کپی، جایگزینی و …)
- امکان تولید گزارشات HTML از نتایج مقایسه
- امکان مقایسهی چند پوشه
- پشتیبانی کامل از انواع فایلهای ویندوزی
- و …
در ادامه چند screenshot از این نرمافزار را میبینیم.
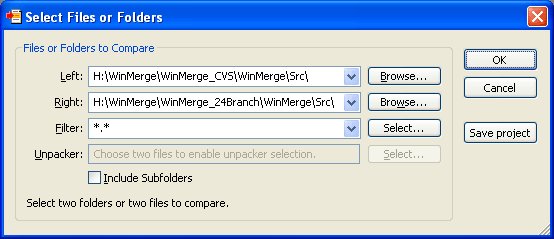
پنجرهی انتخاب فایل ها و پوشهها
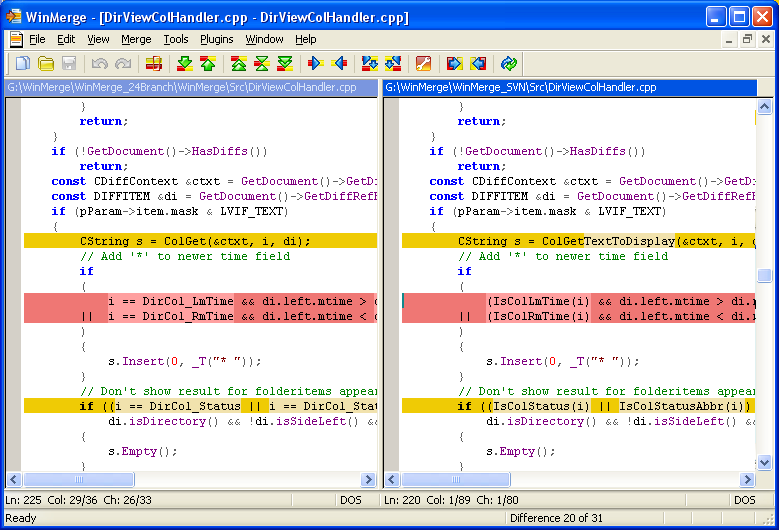
مقایسهی دو فایل
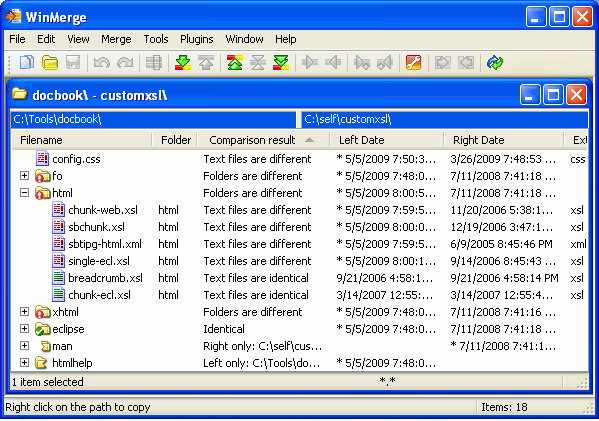
مقایسهی دو پوشه
نتیجهگیری
بنابر آنچه که گفته شد، آلودگی اطّلاعات پدیدهای است که در جوامع اطّلاعاتی در حال گسترش بوده و هر روز، بیش از روز قبل برای صاحبان و کاربران سیستم مشکلزا میشود. به همین دلیل باید از وقوع آن جلوگیری و یا در صورت رخداد آن را از بین برد.
مطلبی که در خاتمه باید به آن اشارهکرد، کاربردهای این روش در سیستمهای اطّلاعاتی است. از این روش میتوان در سیستمهای پشتیبانی از تصمیمگیری، سیستمهای دادهکاوی و دادهپردازی، موتورهای جستجو، سیستمهای خبره، سیستمهای مبتنی بر هوش مصنوعی، سیستمهای مدیریت فنّاوری اطّلاعات، سیستمهای جامع درون سازمانی، رایانههای شخصی، اجتماعات مجازی و شبکههای تحت وب و بخشهای بسیار دیگر استفاده کرد.
از این مطلب میتوان برای گسترش تحقیق در موضوعاتی همچون پایگاههای دادهی هوشمند، بیماریهای اطّلاعاتی، دادهکاوی و دادهپردازی، سیستمهای اطّلاعاتی بهینه و … استفاده کرد. در نهایت، جواب تمامی این تحقیقات، منجر به پیشرفت صنعت رایانه در تولید، نگهداری، پردازش، انتقال و امنیّت اطّلاعات و دیگر موضوعات مربوط به دنیای رایانه و فنّاوری اطّلاعات خواهد شد.
محسن پاک نیت
پاورقی
[۱] Prevention
[۲] Elimination
[۳] Guideline
[۴] Backup Server
[۵] Separator
[۶] Space Key
[۷] Dash
[۸] Hyphen
[۹] Underline
[۱۰] Version Number
[۱۱] Silent


















سلام محسن
مطلب خوبی بود اما یک نظری داشتم این هست که سعی بکن خیلی خلاصه وار و کم متن قراب بده خودم به شخصه اگر مطلبی طولانی ببنیم چند ختش بیشتر نیمخونم و یا اینکه اصلا نمیخونم و یا سعی بکن در چندین قسمت کوتاه مقالت قرار بده که خواننده خسته نشه
همیشه سربلند موفق باشید…
سلام ناصر عزیز.
چشم گل پسر. این مورد رو سعی می کنم رعایت کنم. البته این نوشته از اون جنس نوشته هایی هستش که خواننده های خاص خودش رو داره و درصد کمی از افراد می خوننش. اما همونایی که می خونن هم کامل می خونن. چون فقط کسی دنبال اینجور مطالب میاد که واقعا بهشسون نیاز داره و دنبالشون می گرده.
اما به هر حال پیشنهادت عالیه. مرسی.
شما هم همیشه سربلند و سلامت باشی.